Introduction
Financial statement auditing in Kenya is a painstaking, manual process. Auditors at firms registered with ICPAK (Institute of Certified Public Accountants of Kenya) spend weeks poring over balance sheets, income statements, and transaction ledgers for companies listed on the Nairobi Securities Exchange. They cross-reference every line item against IFRS standards as adopted in Kenya, hunting for misclassifications, numerical errors, missing rows, and redundant entries.
When I came across the paper "Automating Financial Statement Audits with LLMs" by Wang et al. (arXiv:2506.17282v1, 2025), I knew I had to build it. The paper proposes a five-stage framework where an LLM acts as a financial auditor: it reads a financial statement, compares it against transaction data, retrieves relevant accounting standards via RAG, identifies errors, and outputs a corrected statement — all in structured JSON.
This post walks through how I turned that paper into TechStore, a full-stack application with a FastAPI backend, Next.js frontend, and a RAG pipeline grounded in IFRS standards. I'll cover the system architecture, the core auditor agent, prompt engineering with Jinja2 templates, the evaluation framework, and how it all comes together in a streaming web interface.
"We propose a comprehensive five-stage evaluation framework to assess LLM performance across the complete audit workflow, from initial judgment to final statement revision."
— Wang et al., 2025
The Paper's Core Idea
The paper introduces a structured pipeline for LLM-based auditing that mirrors what a human auditor does, broken into five evaluation stages:
- General Judgment — Is the financial statement correct or incorrect?
- Error Identification — What type of error is it (Missing Row, Numerical Error, Redundant Row, Misclassification) and which entry is affected?
- Error Resolution — A natural-language explanation of the error and how to fix it.
- Standards Citation — Which IFRS/IAS standard is relevant?
- Financial Statement Revision — The full corrected table.
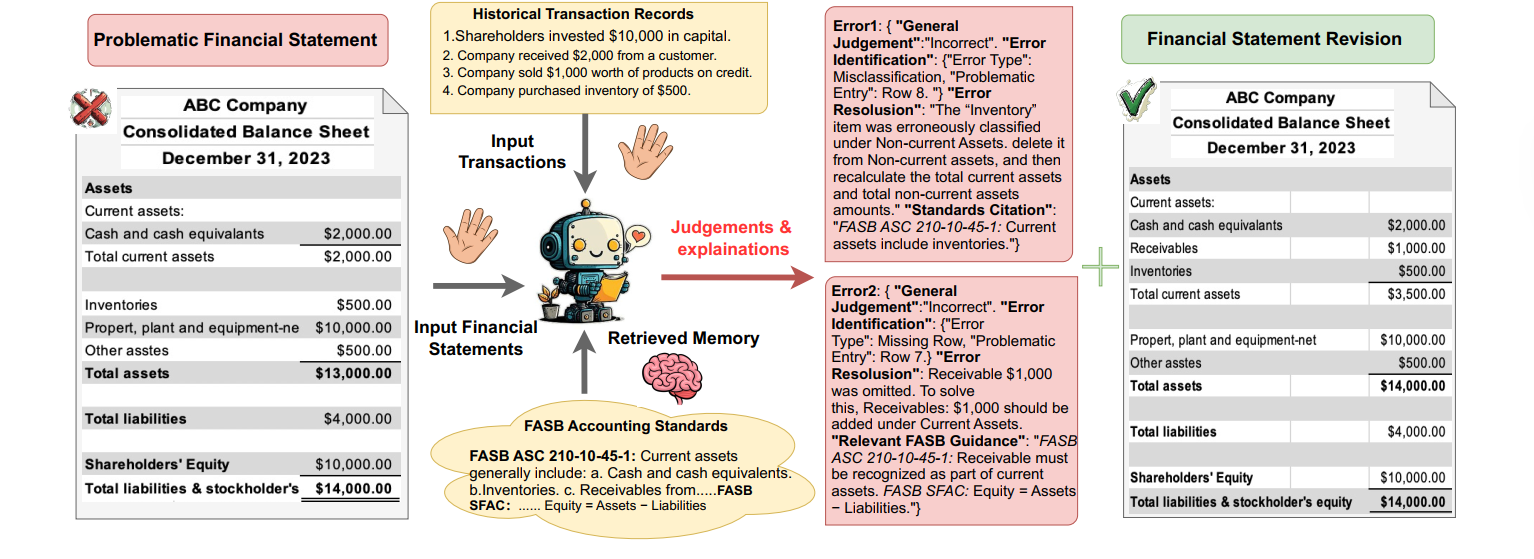
The key insight is that auditing isn't a single yes/no task. Each stage builds on the previous one, and the evaluation metrics differ per stage: Exact Match for judgment and error identification, BERTScore for natural-language resolution, and BLEU for table revision. The paper also introduces a "Retrieved Memory" component — essentially RAG over accounting standards — which significantly improves citation accuracy.
System Architecture
TechStore is structured as a three-layer application:
- Core Engine (Python) — The auditor agent, LLM client, RAG knowledge base, evaluator, and prompt templates. This is framework-agnostic and can run standalone via CLI.
- Backend API (FastAPI) — Exposes the auditor as REST endpoints with SSE (Server-Sent Events) streaming for real-time progress updates.
- Frontend (Next.js) — A web UI where users paste financial statements, trigger audits, and see results rendered in real time.
The core engine handles all the heavy lifting: it orchestrates the LLM call, manages the RAG pipeline with FAISS vector search, parses structured JSON output, and runs the five-stage evaluation. The backend wraps this in an async service layer and streams progress events to the frontend.
Building the LLM Client
The first piece I built was a unified LLM client that abstracts away provider differences. The auditor
needs to work with DeepSeek (for cost-effective development), OpenAI (for benchmarking), and Anthropic
(for comparison). Rather than scattering provider logic throughout the codebase, everything goes through
a single call_llm() function:
def call_llm(
user_prompt: str,
system: str = "",
provider: Optional[str] = None,
model: Optional[str] = None,
temperature: float = 0.0,
max_tokens: int = 4096,
json_mode: bool = False,
) -> str:
"""
Call an LLM with the given prompt. Supports DeepSeek, OpenAI, and Anthropic.
"""
from config import (
LLM_PROVIDER,
DEEPSEEK_API_KEY, DEEPSEEK_MODEL, DEEPSEEK_BASE_URL,
OPENAI_API_KEY, OPENAI_MODEL,
ANTHROPIC_API_KEY, ANTHROPIC_MODEL,
)
provider = provider or LLM_PROVIDER
if provider == "deepseek":
return _call_openai(
user_prompt=user_prompt, system=system,
api_key=DEEPSEEK_API_KEY, model=model or DEEPSEEK_MODEL,
temperature=temperature, max_tokens=max_tokens,
json_mode=json_mode, base_url=DEEPSEEK_BASE_URL,
)
elif provider == "openai":
return _call_openai(
user_prompt=user_prompt, system=system,
api_key=OPENAI_API_KEY, model=model or OPENAI_MODEL,
temperature=temperature, max_tokens=max_tokens,
json_mode=json_mode,
)
elif provider == "anthropic":
return _call_anthropic(
user_prompt=user_prompt, system=system,
api_key=ANTHROPIC_API_KEY, model=model or ANTHROPIC_MODEL,
temperature=temperature, max_tokens=max_tokens,
)
else:
raise ValueError(f"Unsupported LLM provider: {provider}")
DeepSeek uses an OpenAI-compatible API, so both DeepSeek and OpenAI route through the same
_call_openai() helper. Anthropic has its own message format (system prompt is a
top-level parameter, not a message), so it gets a separate _call_anthropic() path.
Temperature is set to 0.0 by default for deterministic auditing output.
The client also includes a parse_json_response() utility that handles LLMs wrapping
JSON in markdown code blocks — a common quirk when requesting structured output.
RAG: Retrieving IFRS Standards
The paper's "Retrieved Memory" component is what makes the auditor actually useful. Without it, the LLM hallucinates standard references. With it, the model can ground its citations in real IFRS text.
I implemented this as the IFRSKnowledgeBase class using FAISS for vector search
and HuggingFace's all-MiniLM-L6-v2 for embeddings:
class IFRSKnowledgeBase:
"""
Vector-based retrieval over IFRS accounting standards
(as adopted in Kenya).
"""
def __init__(self, standards_path: str,
embedding_model: str = "all-MiniLM-L6-v2"):
with open(standards_path, "r") as f:
self.standards = json.load(f)
self.embedding_model_name = embedding_model
self.vectorstore: Optional[FAISS] = None
self._built = False
def build_index(self):
"""Build FAISS vectorstore from standard texts."""
if not HAS_EMBEDDINGS:
print("[KnowledgeBase] langchain/faiss not installed. "
"Using keyword fallback.")
return
embeddings = HuggingFaceEmbeddings(
model_name=self.embedding_model_name
)
documents = []
for s in self.standards:
page_content = (
f"{s['title']}. {s['full_text']} {s['summary']}"
)
metadata = {
"id": s["id"], "standard": s["standard"],
"title": s["title"], "summary": s["summary"],
"full_text": s["full_text"],
}
documents.append(
Document(page_content=page_content, metadata=metadata)
)
self.vectorstore = FAISS.from_documents(documents, embeddings)
self._built = True
def retrieve(self, query: str, top_k: int = 5) -> list[dict]:
"""Retrieve the top-k most relevant IFRS standards."""
if self._built and self.vectorstore is not None:
return self._semantic_retrieve(query, top_k)
else:
return self._keyword_retrieve(query, top_k)
The knowledge base loads IFRS standards from a JSON file where each entry has an id,
standard reference (e.g., "IAS 1"), title, summary, and
full_text. Each standard becomes a LangChain Document with the full text
concatenated for embedding.
The retrieve() method falls back to keyword matching if FAISS or HuggingFace embeddings
aren't available — useful for lightweight deployments or CI environments where you don't want
to download a 90MB embedding model.
The Auditor Agent
The FinancialAuditor class is the heart of the system. Its audit()
method implements the full pipeline from the paper:
class FinancialAuditor:
"""LLM-based financial statement auditor for Kenyan companies."""
def __init__(
self,
knowledge_base: Optional[IFRSKnowledgeBase] = None,
provider: Optional[str] = None,
model: Optional[str] = None,
top_k_standards: int = 5,
):
self.kb = knowledge_base
self.provider = provider
self.model = model
self.top_k = top_k_standards
def audit(
self,
table_text: str,
transactions: str,
use_rag: bool = True,
) -> AuditResult:
"""Run the complete audit pipeline."""
# Step 1: Retrieve relevant standards (RAG)
standards_context = ""
retrieved_standards = []
if use_rag and self.kb:
query = self._build_retrieval_query(
table_text, transactions
)
retrieved_standards = self.kb.retrieve(
query, top_k=self.top_k
)
standards_context = self.kb.format_context(
retrieved_standards, use_summary=False
)
if not standards_context:
standards_context = (
"Use your knowledge of IFRS accounting standards "
"as adopted in Kenya. Cite specific standards "
"(e.g., IAS 1.66, IAS 2.9, IFRS 15) when applicable."
)
# Step 2: Call the LLM auditor
user_prompt = render_auditor_user(
standards_context=standards_context,
table_text=table_text,
transactions=transactions,
)
raw_response = call_llm(
user_prompt=user_prompt,
system=render_auditor_system(),
provider=self.provider,
model=self.model,
temperature=0.0,
)
# Step 3: Parse the response
result = self._parse_audit_response(raw_response)
result.raw_response = raw_response
result.retrieved_standards = retrieved_standards
# Step 4: Enhance citations via RAG
if use_rag and self.kb and result.errors:
self._enhance_citations(result)
return result
The pipeline has four steps: (1) build a retrieval query from the financial statement's row labels
and search the FAISS index for relevant IFRS standards, (2) render the system and user prompts
with the retrieved context and call the LLM, (3) parse the JSON response into an AuditResult
dataclass, and (4) optionally enhance weak citations by running a second RAG lookup per error.
The AuditResult dataclass mirrors the paper's five stages: general_judgment
(Stage 1), a list of AuditError objects each with error_type,
problematic_entry, error_resolution, and standards_citation
(Stages 2–4), and a corrected_table (Stage 5).
Prompt Engineering
Getting the LLM to output structured, accurate audit results required careful prompt design. I used Jinja2 templates to keep prompts maintainable and separate from code.
System Prompt
The system prompt establishes the auditor persona and defines the four error types from the paper:
You are an expert financial statement auditor specialising in
Kenyan companies listed on the Nairobi Securities Exchange (NSE).
Your role is to identify, explain, and correct errors in financial
statements by cross-referencing them with historical transaction
data and accounting standards.
You understand IFRS (International Financial Reporting Standards)
as adopted in Kenya and can cite them accurately (e.g., IAS 1,
IAS 2, IFRS 9, IFRS 15, etc.). You will be provided with:
1. A financial statement that may or may not contain errors
2. The corresponding historical transaction data
3. Relevant accounting standards from your knowledge base
Currency values are in Kenya Shillings (KSh), typically expressed
in millions (KSh' Million) or thousands (KSh' 000).
Error types you should look for:
<1> Missing Row: A row containing a specific account is missing.
<2> Numerical Error: The value of a specific account is incorrect.
<3> Redundant Row: A row that should not exist based on the data.
<4> Misclassification: A row placed in the wrong category.User Prompt
The user prompt injects the retrieved IFRS standards, the financial statement table, and the transaction data, then specifies the exact JSON output format:
Audit the following financial statement by comparing it against
the transaction data.
For your analysis, you also have access to these relevant
accounting standards:
{{ standards_context }}
Provide your output in the following JSON format:
{
"general_judgment": "Correct" or "Incorrect",
"errors": [
{
"error_type": "<Missing Row | Numerical Error | ...>",
"problematic_entry": "Row N",
"error_resolution": "<detailed explanation>",
"standards_citation": "<IFRS/IAS standard reference>"
}
],
"corrected_table": "<the full corrected table>"
}
Input Table:
{{ table_text }}
Transaction Data:
{{ transactions }}
Now analyze and output ONLY the JSON result.
The explicit JSON schema in the prompt is critical. Without it, LLMs tend to produce
free-form text that's impossible to evaluate programmatically. The {% raw %}...{% endraw %}
blocks in the actual template prevent Jinja2 from interpreting the JSON braces as template variables.
Data Pipeline & Benchmarking
The paper uses financial statements from Chinese companies, but I adapted the system for Kenyan companies listed on the NSE. Financial statements are represented in a structured text format where each row is labeled:
[row 1]: Revenue | KSh' Million | 12,450
[row 2]: Cost of Sales | KSh' Million | (8,200)
[row 3]: Gross Profit | KSh' Million | 4,250
[row 4]: Administrative Expenses | KSh' Million | (1,100)
...For benchmarking, I built a data pipeline that:
- Injects errors into clean financial statements — each of the four error types (Missing Row, Numerical Error, Redundant Row, Misclassification) with known ground truth.
- Generates transaction data that corresponds to the correct version of the statement, so the auditor has a reference to compare against.
- Records ground truth for each sample: the correct judgment, error type, affected row, resolution explanation, relevant IFRS standard, and the corrected table.
This gives us a structured benchmark dataset where every sample has a known answer for all five evaluation stages.
The Five-Stage Evaluation Framework
The paper's evaluation framework uses different metrics for different stages, reflecting the
nature of each output. I implemented this in the AuditEvaluator class:
@dataclass
class StageScores:
"""Scores for a single audit sample across all five stages."""
# Stage 1: General Judgment
general_judgment_em: float = 0.0
# Stage 2: Error Identification
error_type_em: float = 0.0
error_entry_em: float = 0.0
# Stage 3: Error Resolution
error_resolution_bertscore: float = 0.0
# Stage 4: Standards Citation
standards_citation_top1_em: float = 0.0
standards_citation_top5_em: float = 0.0
# Stage 5: Table Revision
table_revision_bleu: float = 0.0
# Overall
success: bool = FalseThe evaluate_sample() method computes each metric:
def evaluate_sample(
self,
prediction: "AuditResult",
ground_truth: dict,
retrieved_standard_ids: Optional[list[str]] = None,
) -> StageScores:
"""Evaluate a single audit prediction against ground truth."""
scores = StageScores()
# Stage 1: General Judgment (Exact Match)
gt_judgment = ground_truth.get(
"general_judgment", ""
).strip().lower()
pred_judgment = prediction.general_judgment.strip().lower()
scores.general_judgment_em = (
1.0 if pred_judgment == gt_judgment else 0.0
)
# Stage 2: Error Identification (Exact Match)
if prediction.errors:
pred_error = prediction.errors[0]
gt_type = ground_truth.get("error_type", "").strip().lower()
pred_type = pred_error.error_type.strip().lower()
scores.error_type_em = (
1.0 if pred_type == gt_type else 0.0
)
gt_entry = self._normalize_entry(
ground_truth.get("problematic_entry", "")
)
pred_entry = self._normalize_entry(
pred_error.problematic_entry
)
scores.error_entry_em = (
1.0 if pred_entry == gt_entry else 0.0
)
# Stage 3: Error Resolution (BERTScore)
gt_resolution = ground_truth.get("error_resolution", "")
pred_resolution = (
prediction.errors[0].error_resolution
if prediction.errors else ""
)
scores.error_resolution_bertscore = (
self._compute_bertscore(pred_resolution, gt_resolution)
)
# Stage 4: Standards Citation (Top-K EM)
gt_citation_id = ground_truth.get("standards_citation", "")
if retrieved_standard_ids:
scores.standards_citation_top1_em = (
1.0 if gt_citation_id
in retrieved_standard_ids[:1] else 0.0
)
scores.standards_citation_top5_em = (
1.0 if gt_citation_id
in retrieved_standard_ids[:5] else 0.0
)
# Stage 5: Table Revision (BLEU)
gt_table = ground_truth.get("corrected_table", "")
pred_table = prediction.corrected_table
scores.table_revision_bleu = (
self._compute_bleu(pred_table, gt_table)
)
# Overall Success Rate
scores.success = (
scores.general_judgment_em == 1.0
and scores.error_type_em == 1.0
and scores.error_entry_em == 1.0
and scores.error_resolution_bertscore
>= self.bertscore_threshold
and scores.table_revision_bleu
>= self.bleu_threshold
)
return scoresThe metrics break down as follows:
- Exact Match (EM) for Stages 1, 2, and 4 — binary correctness. The judgment is either right or wrong, the error type matches or it doesn't.
- BERTScore for Stage 3 — semantic similarity between the predicted and ground-truth error resolution. This captures meaning rather than exact wording, with a threshold of 0.85.
- BLEU for Stage 5 — n-gram overlap between the predicted corrected table and the ground truth. Tables are highly structured, so BLEU works well here with a threshold of 0.99.
The overall Success Rate requires all stages to pass their respective thresholds. This is deliberately strict — a real audit that gets the judgment right but cites the wrong standard isn't actually useful.
Bringing It to the Web
The core engine runs as a standalone Python module, but to make it accessible I wrapped it in a FastAPI backend with SSE streaming. Audits can take 10–30 seconds depending on the LLM provider, so streaming progress events keeps the UI responsive.
class AuditService:
"""Wraps FinancialAuditor with async support and SSE streaming."""
async def audit_stream(
self,
table_text: str,
transactions: str,
use_rag: bool = True,
) -> AsyncGenerator[AuditProgressEvent, None]:
"""Yield SSE progress events during the audit."""
yield AuditProgressEvent(
stage="started",
message="Audit started", progress=0.0,
)
yield AuditProgressEvent(
stage="retrieving",
message="Retrieving relevant IFRS standards...",
progress=0.15,
)
yield AuditProgressEvent(
stage="analyzing",
message="Analyzing financial statement with LLM...",
progress=0.30,
)
try:
result = await self.audit(
table_text, transactions, use_rag
)
yield AuditProgressEvent(
stage="parsing",
message="Parsing audit results...",
progress=0.70,
)
yield AuditProgressEvent(
stage="completed",
message="Audit complete", progress=1.0,
data=result.model_dump(),
)
except Exception as e:
yield AuditProgressEvent(
stage="error", message=str(e), progress=0.0,
)
The FastAPI route handler consumes this async generator and converts it to an SSE stream
using sse-starlette:
@router.post("/audit/stream")
async def run_audit_stream(
request: AuditRequestModel,
service: AuditService = Depends(get_audit_service),
):
"""Run an audit with SSE progress streaming."""
async def event_generator():
async for event in service.audit_stream(
table_text=request.table_text,
transactions=request.transactions,
use_rag=request.use_rag,
):
yield {
"event": event.stage,
"data": json.dumps(event.model_dump()),
}
return EventSourceResponse(event_generator())
On the frontend, Next.js connects to the SSE endpoint and updates a progress bar and status
messages in real time. When the completed event arrives with the full audit result,
the UI renders the judgment, error details, standards citations, and the corrected table in a
structured layout.
Key Findings & Lessons Learned
Building this system taught me several things about applying LLMs to structured financial tasks:
What LLMs Excel At
- General Judgment — LLMs are surprisingly good at detecting whether a financial statement contains errors. The binary correct/incorrect judgment achieves high accuracy across providers.
- Error Type Classification — Distinguishing between Missing Row, Numerical Error, Redundant Row, and Misclassification is a natural fit for LLMs that understand accounting semantics.
- Natural-Language Resolution — Explaining why something is wrong and how to fix it is where LLMs truly shine. The BERTScore results for Stage 3 are consistently strong.
Where LLMs Struggle
- Precise Numerical Computation — LLMs sometimes miscalculate totals or fail to propagate corrections through dependent rows. The corrected table (Stage 5) is the hardest stage.
- Standards Citation Without RAG — Without the FAISS knowledge base, models hallucinate IFRS references. RAG is not optional for this task — it's essential.
- Structured Output Consistency — Even with explicit JSON schemas in the prompt, models occasionally deviate from the format. The
parse_json_response()utility with regex fallbacks handles most edge cases, but it's an ongoing battle.
Practical Takeaways
- Temperature 0.0 is non-negotiable for auditing. Any randomness in financial output is unacceptable.
- Jinja2 templates keep prompts maintainable. As prompts grow complex, having them in separate files with variable injection beats string concatenation.
- Keyword fallback in RAG matters. Not every deployment can run FAISS + HuggingFace embeddings. A simple keyword retriever as a fallback keeps the system functional in constrained environments.
- SSE streaming is worth the complexity. A 20-second audit that shows progress feels faster than a 20-second audit with a loading spinner.