Introduction
The Nairobi Securities Exchange is a strange place for algorithmic trading. Daily volumes are thin — some listed stocks go entire sessions without a single trade. Broker commissions eat 2.3% per round trip. Settlement takes three business days. Short selling doesn't exist. And the data infrastructure that US quants take for granted — clean OHLCV feeds, real-time fundamentals APIs, structured sentiment data — simply isn't there for Kenyan equities.
When I came across the TradingAgents paper from UCLA and MIT (arXiv:2412.20138), I saw something that could work here. The paper proposes a multi-agent LLM system where specialized AI analysts — market, fundamentals, news, and sentiment — feed their reports into a structured debate between bull and bear researchers, moderated by a research manager, before a trader and risk management team make the final call. It's designed for US markets with Bloomberg-grade data, but the architecture itself is market-agnostic.
This post walks through how I built TradingAgents — an adaptation of TradingAgents for the NSE. I'll cover the system architecture, how I wired 13 agents in LangGraph, the Kenya-specific data challenges that nearly broke the project, the regulatory constraints I had to encode, and what I learned building a multi-agent system from a research paper for a market that the paper's authors never considered.
"TradingAgents introduces a novel stock trading framework inspired by the dynamics of a trading firm, using LLM-powered agents that collaboratively analyze data and make informed decisions."
— Xiao et al., TradingAgents (UCLA/MIT), 2024
The Paper's Core Idea
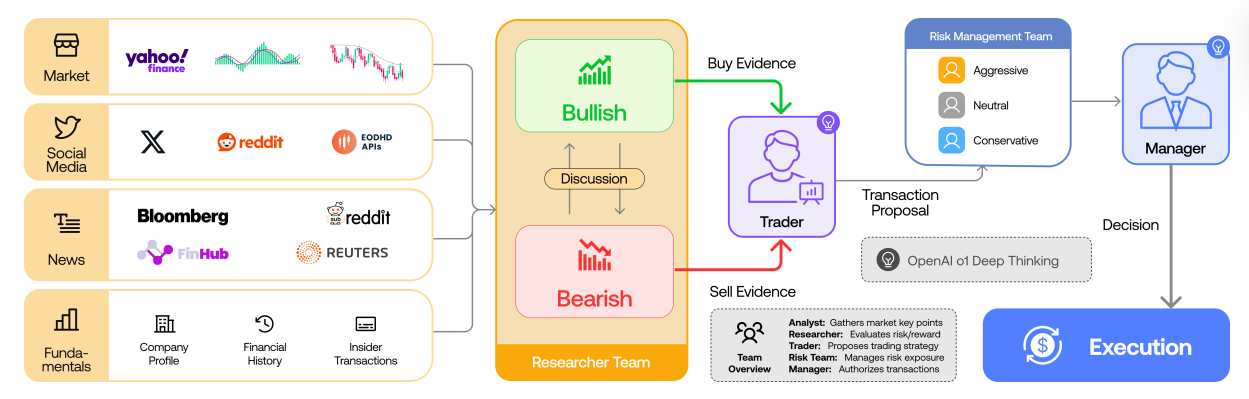
TradingAgents models a trading firm as a collection of specialized agents. Instead of one monolithic LLM making a BUY/SELL/HOLD decision, the paper breaks the process into the same roles you'd find at a hedge fund:
- Analyst Team (4 agents) — Each agent specializes in one data domain: technical/market data, company fundamentals, news & macro, and social sentiment. They produce independent reports.
- Research Debate (2 agents + 1 manager) — A bull researcher makes the strongest case for buying, a bear researcher argues for selling, and they debate for multiple rounds. A research manager synthesizes the debate outcome.
- Trader (1 agent) — Takes all analyst reports plus the debate summary and produces a concrete BUY/SELL/HOLD signal with quantity and confidence.
- Risk Management (3 agents) — An aggressive, conservative, and neutral risk manager debate position sizing and risk constraints.
- Fund Manager (1 agent) — The final authority. Reviews everything and makes the execution decision.
The key insight is that debate improves decision quality. A single LLM tends to anchor on its first impression. Forcing explicit bull/bear arguments surfaces edge cases and counterarguments that a single-pass analysis misses.
Why the NSE Needed Different Thinking
The original paper targets US equities — liquid markets with T+1 settlement, near-zero commissions, short selling, and decades of clean historical data. The NSE is a different world. Before writing any code, I had to understand what would break.
Transaction Costs Kill Small Moves
In the US, commission-free brokers like Robinhood mean a 2% price move is pure profit. On the NSE, you pay approximately 2.34% in fees on every round trip:
# CMA and NSE regulatory constraints
BROKER_COMMISSION_RATE = 0.018 # 1.8% of transaction value
CDS_FEE_RATE = 0.0008 # 0.08% CDSC (Central Depository) fee
NSE_TRANSACTION_LEVY = 0.0012 # 0.12% NSE levy
CMA_LEVY = 0.0014 # 0.14% CMA levy
TOTAL_TRANSACTION_COST = (
BROKER_COMMISSION_RATE + CDS_FEE_RATE
+ NSE_TRANSACTION_LEVY + CMA_LEVY
) # ~2.34% per side
SETTLEMENT_DAYS = 3 # T+3 (NOT T+1 like US)
SHORT_SELLING_ALLOWED = False # No shorting on NSEThis means a stock needs to move at least 4.68% (buy + sell costs) just to break even. The original paper's agents don't account for this — they'll happily recommend trades on 1-2% signals that would lose money after Kenyan fees. Every agent in TradingAgents has this cost structure baked into its reasoning prompts.
T+3 Settlement Locks Capital
When you sell shares on the NSE, you don't get your money for three business days. In the backtesting engine, I track settlement explicitly — funds from a Monday sale aren't available until Thursday. This prevents the system from making rapid trades that assume instant liquidity, which is exactly what the paper's agents would do in a US context.
No Short Selling
The paper's bear researcher can recommend selling shares the portfolio doesn't hold. On the NSE, that's illegal. TradingAgents's trader agent is hard-coded to only sell shares it actually owns. A bearish signal for a stock not in the portfolio simply maps to HOLD.
Illiquidity Is the Real Risk
Some NSE stocks trade less than KES 1 million per day. If the system decides to buy 100,000 shares of a small-cap stock, it could move the market by trying to fill that order. The risk management agents explicitly check proposed trade sizes against average daily volume — if the order exceeds 10% of ADV, the conservative risk manager flags it.
System Architecture
TradingAgents follows a three-layer architecture, similar to my previous projects:
- Core Engine (Python) — The LangGraph multi-agent system, data layer with 8 providers, NSE domain module, backtesting engine, and LLM client factory. This runs standalone via CLI or as a library.
- Backend API (FastAPI) — Exposes analysis and backtesting as async job endpoints. Clients submit a ticker + date, poll for results, and receive the full 13-agent decision breakdown.
- Frontend (Next.js) — Dashboard with ticker browser, analysis form, backtest visualizations (equity curves, trade logs, Sharpe ratios), and tabbed views of all agent reports.
The core engine is where all the interesting work happens. The API and frontend are relatively straightforward wrappers — the hard problems are in the agent orchestration and the data layer.
Wiring 13 Agents in LangGraph
LangGraph is a library for building stateful, multi-step LLM workflows as directed graphs. Each node is an agent function that reads from and writes to a shared state object. Edges define the flow between agents, and conditional edges enable loops (like debate rounds).
Here's the core state that flows through the entire pipeline:
class AgentState(BaseModel):
"""Main state passed through the trading graph."""
# Identifiers
ticker: str = ""
date: str = ""
# LLM message history
messages: Annotated[list[BaseMessage], add_messages] = Field(
default_factory=list
)
# Analyst reports (filled by each analyst agent)
market_report: str = ""
fundamentals_report: str = ""
news_report: str = ""
sentiment_report: str = ""
# Research debate
bull_case: str = ""
bear_case: str = ""
debate_history: list[str] = Field(default_factory=list)
debate_round: int = 0
research_summary: str = ""
# Trader decision
trader_signal: str = "" # BUY / SELL / HOLD
trader_confidence: float = 0.0
trader_quantity: int = 0
# Risk management debate
risk_debate_history: list[str] = Field(default_factory=list)
risk_debate_round: int = 0
# Fund manager final decision
final_decision: str = "" # BUY / SELL / HOLD
final_quantity: int = 0
final_reasoning: str = ""
# Portfolio context (from backtest engine or API)
portfolio_value: float = 1_000_000.0
cash_available: float = 1_000_000.0
current_position: int = 0
# Memory / reflection
memory_context: str = ""
reflection: str = ""
Each analyst writes to its own field (market_report,
fundamentals_report, etc.), so there are no write conflicts when running
them in parallel. The debate agents append to debate_history and
risk_debate_history. The trader and fund manager write to
trader_signal and final_decision respectively.
The graph wiring defines the full topology:
def build_trading_graph(config: dict | None = None) -> StateGraph:
"""Build the TradingAgents trading graph.
Topology:
START -> parallel_analysts (4 concurrent) ->
research debate (2 rounds) -> trader ->
risk debate (2 rounds) -> fund manager ->
reflection -> END
"""
graph = StateGraph(AgentState)
# Parallel analyst node (4 agents at once)
graph.add_node("parallel_analysts", parallel_analysts_node)
# Research debate nodes
graph.add_node("bull_researcher", bull_researcher_node)
graph.add_node("bear_researcher", bear_researcher_node)
graph.add_node("debate_round_inc", increment_debate_round)
graph.add_node("research_manager", research_manager_node)
# Trader
graph.add_node("trader", trader_node)
# Risk debate nodes
graph.add_node("aggressive_risk", aggressive_risk_node)
graph.add_node("conservative_risk", conservative_risk_node)
graph.add_node("neutral_risk", neutral_risk_node)
graph.add_node("risk_round_inc", increment_risk_debate_round)
# Fund manager + reflection
graph.add_node("fund_manager", fund_manager_node)
graph.add_node("reflection", reflection_node)
# === EDGES ===
graph.set_entry_point("parallel_analysts")
graph.add_edge("parallel_analysts", "bull_researcher")
# Research debate loop
graph.add_edge("bull_researcher", "bear_researcher")
graph.add_edge("bear_researcher", "debate_round_inc")
graph.add_conditional_edges(
"debate_round_inc",
should_continue_debate,
{
"continue_debate": "bull_researcher",
"end_debate": "research_manager",
},
)
graph.add_edge("research_manager", "trader")
graph.add_edge("trader", "aggressive_risk")
# Risk debate loop
graph.add_edge("aggressive_risk", "conservative_risk")
graph.add_edge("conservative_risk", "neutral_risk")
graph.add_edge("neutral_risk", "risk_round_inc")
graph.add_conditional_edges(
"risk_round_inc",
should_continue_risk_debate,
{
"continue_risk": "aggressive_risk",
"end_risk": "fund_manager",
},
)
graph.add_edge("fund_manager", "reflection")
graph.add_edge("reflection", END)
return graph
The conditional edges are what make the debate work. After each bull/bear exchange, a
counter increments and should_continue_debate() checks if we've hit the
maximum rounds (default: 2). The same pattern applies to the risk debate. This gives us
structured, bounded argumentation without infinite loops.
Running Analysts in Parallel
The original paper runs analysts sequentially. With four analysts each making an LLM call
(plus data fetching), that's 30–60 seconds of sequential waiting. I replaced this
with a parallel execution node using Python's ThreadPoolExecutor:
def parallel_analysts_node(state: AgentState) -> dict:
"""Run all 4 analysts concurrently.
Each analyst writes to its own state key so there
are no write conflicts. Cuts ~30-60 seconds off
the pipeline compared to sequential execution.
"""
analysts = [
market_analyst_node,
fundamentals_analyst_node,
news_analyst_node,
sentiment_analyst_node,
]
merged: dict = {}
with ThreadPoolExecutor(max_workers=4) as executor:
futures = {
executor.submit(_run_analyst, fn, state): fn
for fn in analysts
}
for future in as_completed(futures):
try:
result = future.result(timeout=60)
if result:
merged.update(result)
except Exception as e:
logger.warning("Analyst %s failed: %s",
futures[future].__name__, e)
return merged
This is safe because each analyst writes to its own state key. The market analyst fills
market_report, the fundamentals analyst fills fundamentals_report,
and so on. No race conditions, no locks needed. In practice, this cuts the pipeline from
~60 seconds to ~15–20 seconds — the longest single analyst call becomes the
bottleneck instead of the sum of all four.
The Data Problem: Scraping the NSE
This was the hardest part of the entire project. The paper assumes clean, API-accessible data. For the NSE, that doesn't exist. There's no Bloomberg Terminal for Kenyan equities. There's no free API that gives you OHLCV, fundamentals, news, and sentiment for NSE stocks in one place.
I built a data layer with 8 providers and a vendor routing system that falls through a priority chain until something works:
class DataInterface:
"""Routes data requests to the best available provider.
Provider priority is configured per data type.
On failure, falls through to the next provider.
"""
def get_ohlcv(self, symbol: str, start_date: str,
end_date: str) -> pd.DataFrame:
"""Fetch OHLCV using the priority chain."""
for provider_name in self.config["ohlcv_providers"]:
provider = self._providers.get(provider_name)
if provider is None:
continue
try:
df = provider.get_ohlcv(symbol, start_date, end_date)
if not df.empty:
return df
except Exception as e:
logger.warning("Provider %s failed: %s",
provider_name, e)
return pd.DataFrame()The priority chains look like this:
- OHLCV: StockAnalysis → NSE Scraper (afx.kwayisi.org) → Yahoo Finance (.NR suffix) → EODHD
- News: Kenyan RSS feeds (Business Daily, Nation, Standard) → EODHD
- Sentiment: Twitter/X (Kenya geo-filter) → Reddit r/Kenya
- Macro: CBK website (Central Bank Rate, T-bills, FX) → World Bank API
- Fundamentals: EODHD (paid) → NSE scraper
The NSE scraper pulls from afx.kwayisi.org, which is the most reliable free
source for NSE daily prices. Yahoo Finance works for major tickers using the
.NR suffix (e.g., SCOM.NR for Safaricom), but it's incomplete
for smaller listings. EODHD has the best fundamentals data but requires a paid API key.
For macro data, I scrape the Central Bank of Kenya website directly — CBK publishes the Central Bank Rate, T-bill rates (91-day, 182-day, 364-day), interbank rates, and KES/USD exchange rates. This feeds into the news analyst's macro context, which is critical for the Kenyan market where CBK MPC decisions move bank stocks significantly.
Making Agents Think Like Kenyan Analysts
The paper's agents use generic prompts designed for US markets. For TradingAgents, every agent prompt was rewritten with Kenya-specific context. This is where the real adaptation happens — not in the architecture, but in the domain knowledge encoded in the prompts.
Market Analyst
The market analyst uses shorter moving averages (20/50-day instead of 50/200-day) because NSE stocks have thin liquidity and longer-term technicals are unreliable. ATR (Average True Range) is used not just for volatility but as a proxy for liquidity — if ATR is extremely low, the stock might be too illiquid to trade. The analyst also monitors volume trends explicitly, since many NSE stocks trade less than KES 1 million per day.
Fundamentals Analyst
NSE valuations are very different from US markets. The average P/E ratio on the NSE sits between 5–12x (compared to 15–25x in the US). Dividend yield is a major driver — many Kenyan investors buy and hold blue-chips like Safaricom, KCB, and Equity Bank primarily for dividends. The fundamentals analyst weights dividend yield heavily and uses Kenya-specific metrics: NPL ratios and capital adequacy for banks, M-Pesa revenue share for Safaricom, and export volumes for agricultural stocks.
News & Macro Analyst
This agent monitors CBK Monetary Policy Committee decisions, T-bill rates (the 91-day T-bill at ~16.5% is the risk-free benchmark, not the US Fed rate), KES/USD exchange rate movements, and Kenya-specific macro indicators like tea/coffee export revenues, drought conditions, and government debt levels. A CBK rate hike moves bank stocks immediately — the news analyst needs to understand this.
Bull and Bear Researchers
The bull researcher draws on Kenya's demographic dividend (young population), M-Pesa and mobile money innovation, EAC trade integration, and the "Silicon Savannah" tech narrative. The bear researcher counters with KES depreciation pressure, high government debt (~70% of GDP), drought and climate risk, NSE illiquidity, and the fact that 91-day T-bills yield ~16.5% risk-free — why take equity risk when government paper pays that much?
Risk Managers
The three risk managers (aggressive, conservative, neutral) all check NSE-specific constraints: Can you actually exit this position given daily volumes? Does the proposed trade size exceed 10% of average daily volume? Is the expected return large enough to overcome the 4.68% round-trip cost? The conservative risk manager also factors in political event risk (elections, policy changes) and KES depreciation risk for export-sensitive companies.
Running the Pipeline
The TradingAgentsGraph class is the main entry point. It builds the graph on
initialization, then exposes a single propagate() method that runs the
full 13-agent pipeline:
class TradingAgentsGraph:
"""Multi-agent trading graph for NSE equities."""
def __init__(self, config: dict | None = None):
self.config = config or DEFAULT_CONFIG
self.memory = AgentMemory()
self._graph = build_trading_graph(self.config)
self._compiled = self._graph.compile()
def propagate(
self,
ticker: str,
date: str,
portfolio_context: dict | None = None,
) -> tuple[dict, dict]:
"""Run the full multi-agent pipeline.
Returns (final_state, decision) where decision
has action, quantity, reasoning, confidence.
"""
initial_state = create_initial_state(
ticker=ticker,
date=date,
memory=self.memory,
)
if portfolio_context:
initial_state.update(portfolio_context)
final_state = self._compiled.invoke(
initial_state,
config={"recursion_limit": 50},
)
decision = {
"ticker": ticker,
"date": date,
"action": final_state.get("final_decision", "HOLD"),
"quantity": final_state.get("final_quantity", 0),
"reasoning": final_state.get("final_reasoning", ""),
"trader_confidence": final_state.get(
"trader_confidence", 0.0
),
"reflection": final_state.get("reflection", ""),
}
return final_state, decision
The memory component deserves a note. After every decision, a reflection
node saves the ticker, decision, reasoning, confidence, and a self-critique to a JSON
file (data/memory/{TICKER}.json). The next time the same ticker is analyzed,
this history is injected into the initial state so the agents can learn from past
decisions. It's a simple rolling window of 50 entries per ticker, but it meaningfully
reduces repeated mistakes.
Running It: Safaricom (SCOM) Analysis
To see the system in action, we ran a full analysis on Safaricom PLC (SCOM) — the most traded stock on the NSE, accounting for roughly 25% of the NSE 20 index weight. Here's what the pipeline looks like end to end.
The analysis form takes three inputs: ticker (SCOM), date (02/19/2026), and LLM provider (DeepSeek). Hit "Run Analysis" and the 13-agent pipeline kicks off. The backend logs show the data providers firing — you can see RSS fetches failing for Nation and Standard (403/404 errors), all news providers falling through, and CBK rates returning a 404. This is the fallback chain doing its job: failures are expected, the system keeps going.
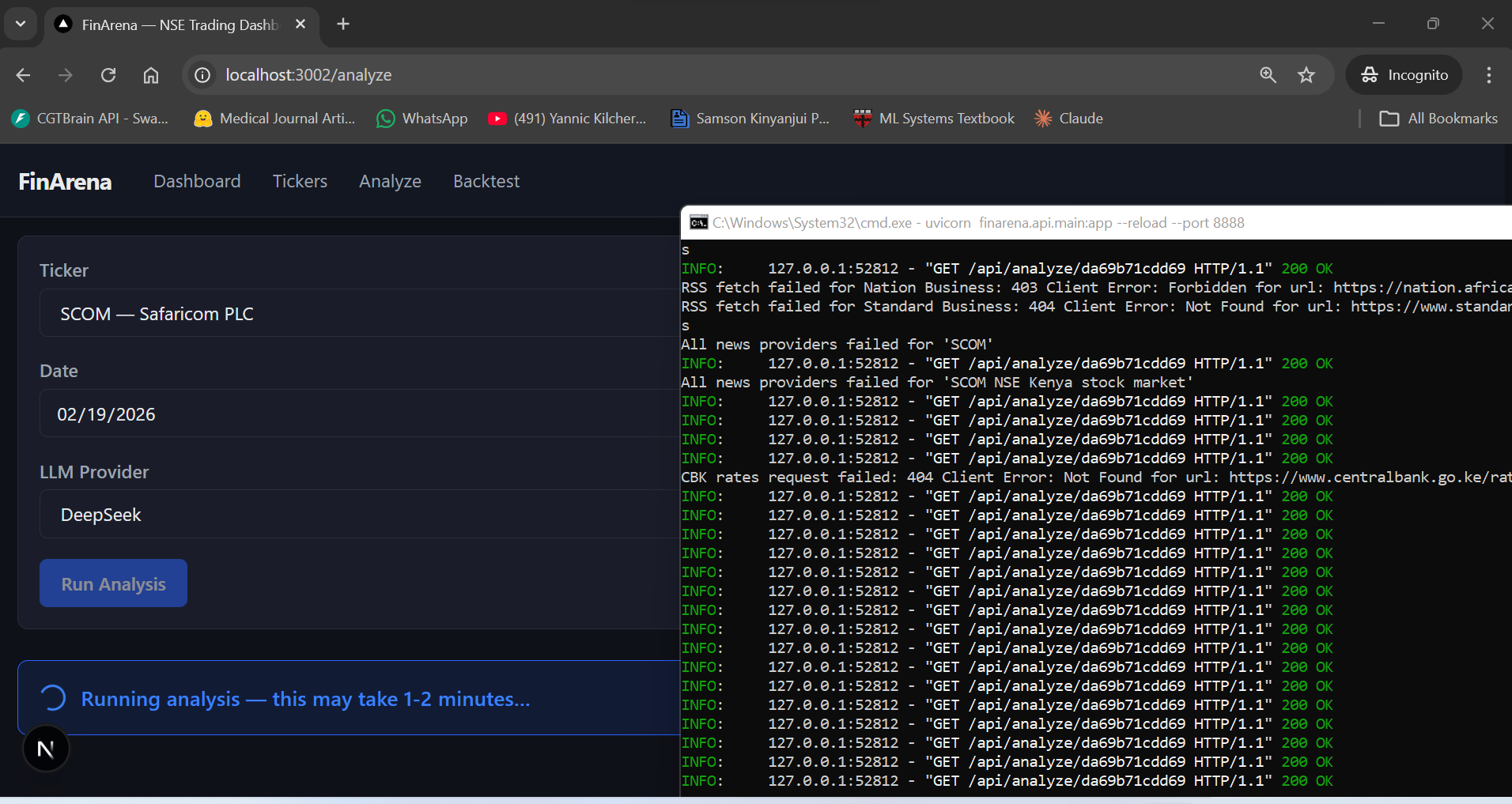
After about 90 seconds, the result comes back. The fund manager's final decision: HOLD with 80% confidence. The reasoning is interesting — it cites the 16.5% T-bill yield as a "superior, active alternative to equity risk in SCOM at current levels" and recommends "mandatory reallocation of capital to T-bills" as "disciplined frontier market risk management."
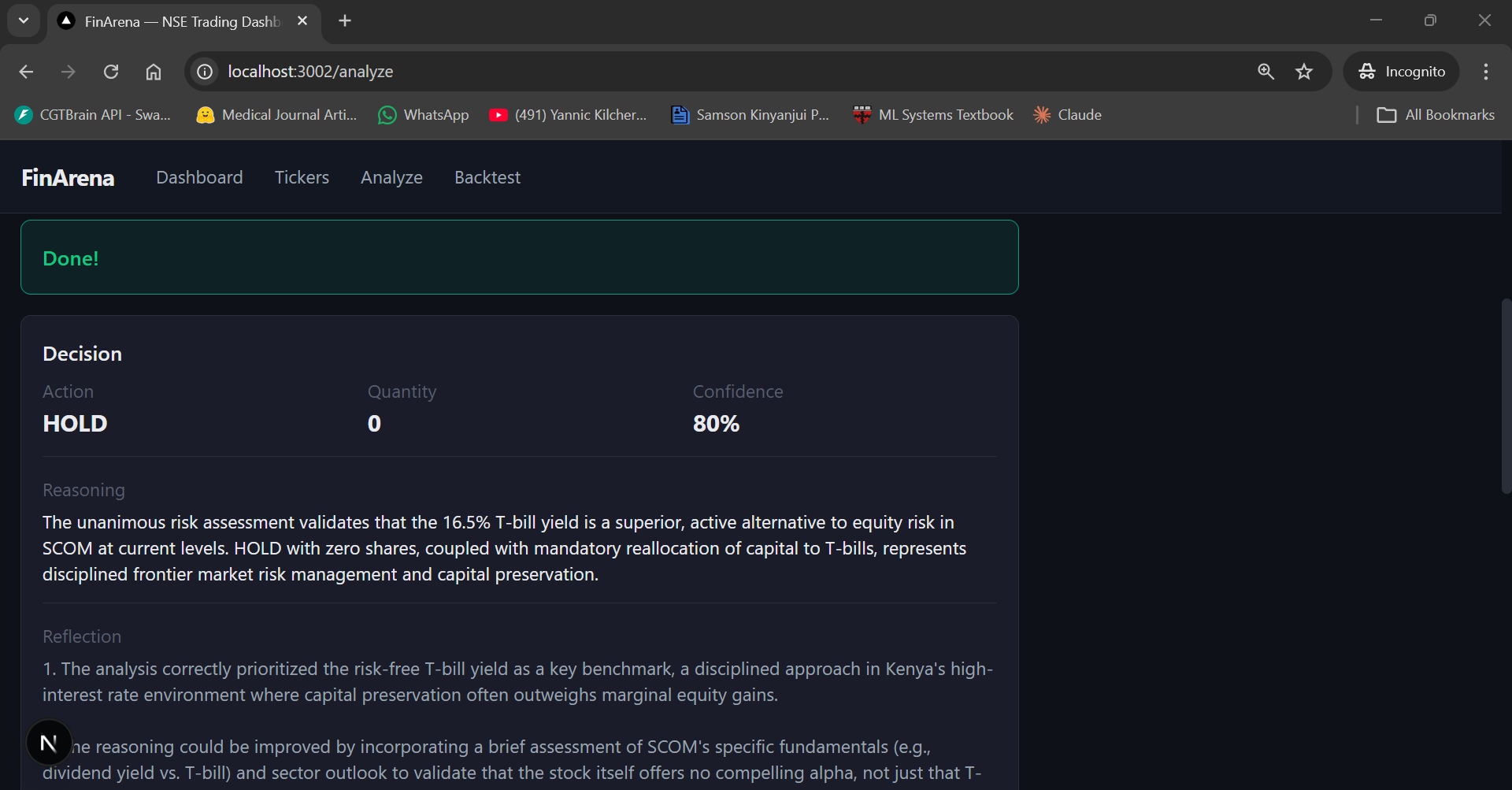
Below the decision, the UI shows each agent's full report in expandable accordion panels. The Market Analysis tab reveals detailed technical analysis: SCOM at KES 33.10, RSI at 74.45 (overbought territory), price above the 20-day and 50-day SMAs but dipping below the 5-day SMA, and MACD histogram narrowing — signs of decelerating momentum.
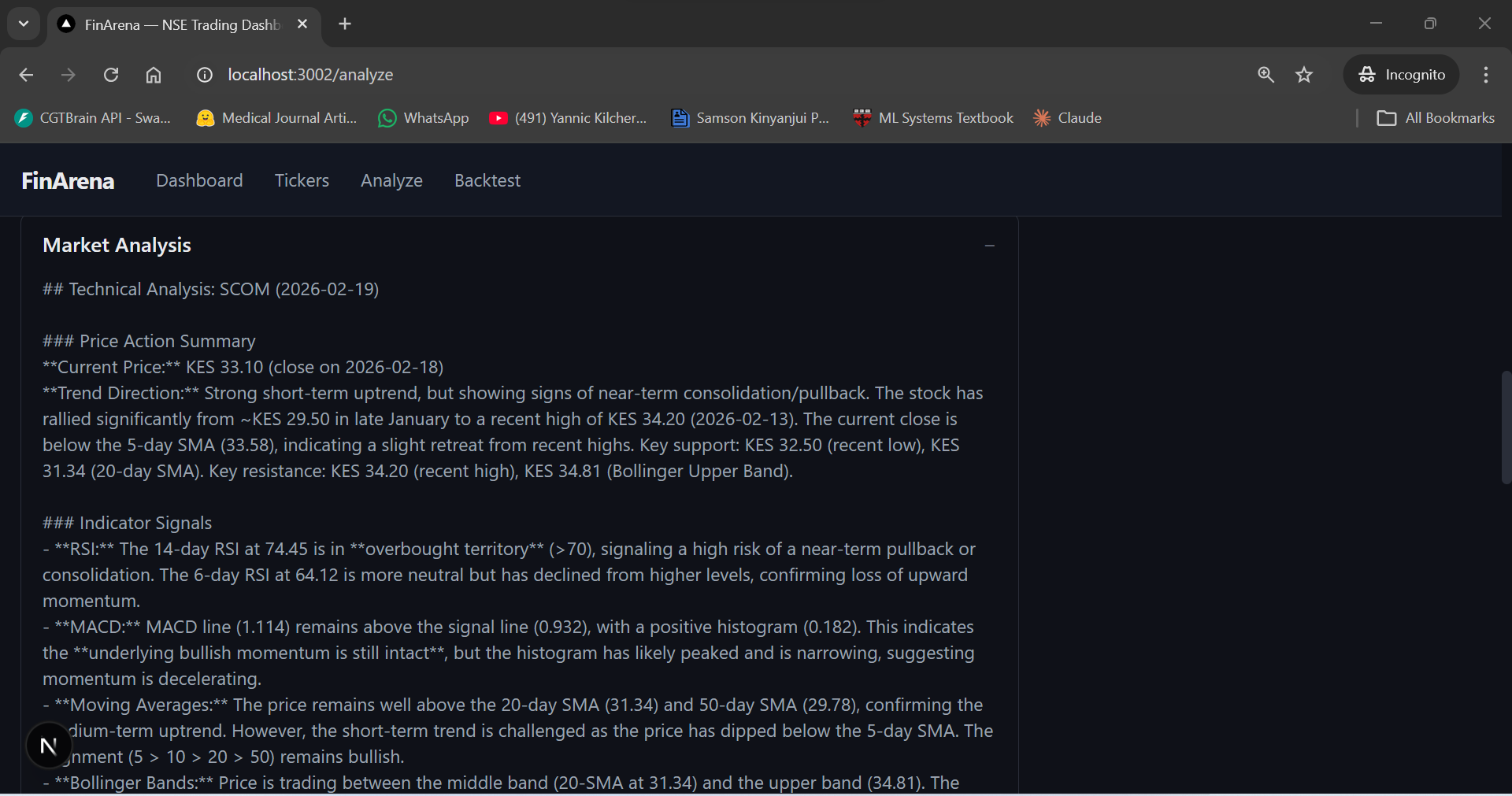
The Research Summary shows where the debate landed: MIXED with a BEARISH TILT (Near-Term). The bull case acknowledges SCOM's structural dominance (M-Pesa, digital infrastructure, young demographics) and resilient profitability (ROE >25%, EBITDA ~50%). The bear case wins on near-term timing — with T-bills at 16.5% and the stock in overbought territory, the risk/reward doesn't justify a new position.
The full output includes 12 expandable report sections — Market Analysis, Fundamentals, News, Sentiment, Bull Case, Bear Case, Research Summary, Trader Signal, Trader Reasoning, Risk Assessment, Final Decision, and Final Reasoning. Every step of the 13-agent pipeline is transparent and auditable.
LLM Provider Strategy: Why DeepSeek
The system supports four LLM providers (DeepSeek, OpenAI, Anthropic, Ollama), but DeepSeek is the default for a practical reason: cost. A single analysis run makes roughly 16 LLM calls — 4 analyst calls (quick model) plus ~12 debate/synthesis calls (deep model). With OpenAI GPT-4o, that's roughly $0.50–$1.00 per analysis. With DeepSeek, it's less than $0.05.
The system uses two model tiers:
- Quick model (
deepseek-chat) — Used by the four analysts for data interpretation. These calls process pre-fetched data and produce structured reports. Speed matters more than deep reasoning here. - Deep model (
deepseek-reasoner) — Used by the debate agents, research manager, trader, risk managers, and fund manager. These calls require multi-step reasoning, weighing conflicting evidence, and producing nuanced arguments.
One gotcha with deepseek-reasoner: it doesn't support temperature control
or function calling. All prompts had to be designed for structured text output (parsed
with regex) rather than tool-use patterns. This is actually fine for our use case —
the agents don't need to call tools dynamically because all data is pre-fetched before
the LLM is invoked.
Pre-fetched Data, Not Tool Calling
The paper uses a tool-calling pattern where agents decide what data to fetch during their reasoning loop. I tried this initially and abandoned it. The problem is speed: each tool call adds a round-trip to the data provider, and the LLM often makes redundant or poorly formatted requests. With 4 analysts making 2–3 tool calls each, the pipeline ballooned to 3+ minutes.
Instead, each analyst pre-fetches all relevant data before the LLM is invoked. The market analyst fetches 90 days of OHLCV data and computes technical indicators (SMAs, RSI, MACD, Bollinger Bands, ATR) upfront. The news analyst fetches CBK rates, FX data, inflation numbers, and recent headlines. All of this is formatted as context strings and passed to the LLM in a single call.
This is a departure from the paper, but it's a pragmatic one. The LLM's job is interpretation, not data retrieval. It reads pre-formatted analyst briefs and produces a report. One LLM call per analyst, deterministic data, no retry loops.
Backtesting with NSE Constraints
The backtesting engine runs the full 13-agent pipeline for every trading day in a date
range. For each day, it fetches the current price, runs TradingAgentsGraph.propagate()
with the portfolio context, and executes the decision. What makes it NSE-specific:
- KES accounting — All portfolio values, P&L, and fees are in Kenya Shillings, not USD. The risk-free rate for Sharpe ratio calculation uses the CBK 91-day T-bill rate (~16.5%), not the US Fed rate.
- T+3 settlement tracking — Funds from a sale are marked unavailable for 3 business days. The portfolio object tracks pending settlements and only releases cash after the settlement period.
- NSE calendar — Skips weekends and Kenyan public holidays (Madaraka Day, Mashujaa Day, Jamhuri Day, etc.). Trading hours are 09:00–15:00 EAT (UTC+3).
- Full transaction costs — Every trade deducts the 2.34% commission + levies from the portfolio, matching real-world execution costs.
Problems We Faced
Building TradingAgents was not a clean paper-to-code translation. Here's what actually went wrong.
Data Providers Go Down Constantly
The afx.kwayisi.org scraper — our primary price source — returns empty data unpredictably. The CBK website changes its HTML structure without warning. Twitter's API rate limits kick in during peak hours. This is why the fallback chain architecture isn't optional — it's survival. I built the system to assume that any single provider will fail, and only error out when all providers in a chain fail for the same data type.
LLM Output Parsing Is Fragile
The trader agent is supposed to output a structured signal:
Signal: BUY, Quantity: 100,
Confidence: 0.75. In practice, LLMs output this in dozens of variations:
"My signal is BUY", "I recommend buying", "Signal — BUY", etc.
The signal parser uses regex with multiple fallback patterns, and still occasionally
fails on unexpected formatting. When parsing fails, the system defaults to HOLD with
0 quantity — the safe fallback.
Debate Rounds Can Produce Repetitive Arguments
With 2 rounds of bull/bear debate, the second round sometimes just restates the first round's arguments with different wording. The research manager is instructed to ignore repetitive points and focus on any new evidence introduced in later rounds. In practice, the second round adds meaningful nuance about 60% of the time. Running 3+ rounds showed diminishing returns.
Small-Cap NSE Stocks Have Zero Data
For blue-chips like Safaricom (SCOM), KCB, and Equity Bank (EQTY), data is reasonably available. For smaller stocks like Limuru Tea (LIMT) or Crown Paints (CRWN), the news provider returns nothing, the sentiment provider finds no tweets, and fundamentals data is sparse. The agents handle this gracefully — they note the data gaps in their reports and reduce confidence accordingly — but the decisions for small-caps are inherently lower quality.
DeepSeek Reasoner Doesn't Support System Prompts Properly
We discovered that deepseek-reasoner ignores the system prompt in certain
configurations. The fix was to prepend the persona and constraints directly into the user
prompt for the reasoning model, while keeping the cleaner system/user separation for
deepseek-chat.
What We Learned
Building a multi-agent system from a research paper for a market the paper never considered taught us several things:
The Architecture Is Market-Agnostic, the Data Isn't
The TradingAgents framework — analysts, debate, trader, risk managers, fund manager — translates directly to any market. What doesn't translate is the data infrastructure. 70% of the development effort went into the data layer: finding providers, building scrapers, handling failures, and caching responses. The agent code itself was relatively straightforward once the data was flowing.
Domain Knowledge Lives in the Prompts
The single most impactful change from the paper to TradingAgents wasn't architectural — it was rewriting every prompt with NSE-specific knowledge. T+3 settlement, KES commissions, dividend-driven valuations, CBK policy impacts, T-bill opportunity costs, frontier market illiquidity. An LLM with a generic "analyze this stock" prompt makes generic (bad) decisions. An LLM told "you're analyzing a Kenyan bank stock where NPL ratios matter and T-bills yield 16.5%" makes meaningfully different recommendations.
Pre-fetching Beats Tool Calling for Structured Workflows
When you know exactly what data each agent needs (and you do in a trading system), there's no reason to let the LLM decide what to fetch. Pre-fetching is faster, more reliable, and produces deterministic data inputs. Tool calling makes sense for open-ended tasks; for structured analytical pipelines, it's overhead.
Debate Actually Helps
The bull/bear debate isn't just a gimmick. In our testing, decisions that went through 2 rounds of debate were more conservative and cited more data points than single-pass decisions. The debate forces the system to consider counterarguments explicitly, which is especially valuable in a frontier market where risks are easy to overlook.
Frontier Markets Need Defensive Defaults
The most important agent in the system is the conservative risk manager. In a market with 2.34% transaction costs, T+3 settlement, and daily volume under KES 10M for most stocks, the default should be "don't trade." The system earns its value not by making more trades, but by correctly identifying the few situations where the signal is strong enough to overcome the friction.
Further Reading
- TradingAgents: Multi-Agents LLM Financial Trading Framework (Xiao et al., UCLA/MIT, 2024)
- LangGraph Documentation — Stateful Multi-Agent Workflows
- Nairobi Securities Exchange — Official Website
- Central Bank of Kenya — Monetary Policy & Rates
- Capital Markets Authority (CMA) Kenya
- DeepSeek API Documentation